The Ai Governance Gap: the Hard Questions the World Still Hasn't Answered
AI is advancing exponentially. Governance is not.
This is not a philosophical observation. It is an operational reality that affects every organization deploying AI systems, every government writing AI policy, and every individual whose data is being used to train the models reshaping the global economy.
Across jurisdictions, industries, and institutions, major questions remain unsettled. Not minor technical questions. Foundational questions about ownership, accountability, fairness, and control. The kind of questions that determine whether AI becomes a tool that serves society or a force that outpaces it.
Here is a structured view of the eight governance gaps shaping the AI economy today.
1. Data and Privacy
The foundation models that power modern AI were trained on data. Enormous quantities of data. And the governance questions around that data remain largely unresolved.
Who owns training data used in foundation models? When a model is trained on billions of web pages, books, images, and code repositories, who holds rights to that data? The creators who produced it? The platforms that hosted it? The companies that scraped it? The model developers who transformed it into weights? Current law was not designed for this question, and different jurisdictions are arriving at different answers.
Is scraped public data lawful training data? Just because something is publicly accessible does not mean it is legally available for commercial AI training. The distinction between public access and commercial use is being litigated right now, with cases that could reshape the economics of AI development. The New York Times lawsuit against OpenAI is one example. There will be more.
Cross-border data transfer conflicts are accelerating. The EU's GDPR, China's data localization requirements, and evolving US frameworks create a patchwork of incompatible rules. A model trained on data from multiple jurisdictions may be legal in one country and illegal in another, and there is no global framework to resolve the conflict.
Re-identification risks in anonymized data are real and growing. Research has repeatedly demonstrated that supposedly anonymized datasets can be re-identified using auxiliary information. As AI systems become better at pattern recognition, the gap between anonymized and identifiable narrows. The governance frameworks that rely on anonymization as a privacy safeguard may be built on an increasingly unstable foundation.
2. Bias and Fairness
AI systems learn from data, and data reflects the world as it is, not as it should be. The result is systematic bias embedded in systems that are increasingly used for consequential decisions.
Algorithmic discrimination in hiring, lending, and healthcare is not theoretical. It is documented. Amazon's recruiting tool that penalized women. Apple Card's credit algorithm that offered lower limits to women. Healthcare algorithms that systematically underserved Black patients. These are not edge cases. They are the predictable result of training systems on historically biased data without adequate fairness constraints.
Non-representative datasets compound the problem. When training data underrepresents certain populations, the resulting models perform worse for those populations. This is not a bug. It is a structural feature of how machine learning works, and it requires deliberate intervention to correct.
There are no standardized bias audits. Every organization that claims to test for bias is using its own methodology, its own metrics, and its own definition of fairness. Without standardization, bias auditing is inconsistent, incomparable, and often inadequate.
Global versus local fairness standards create additional complexity. What constitutes fair treatment varies across cultures, legal systems, and social contexts. A model that meets US fairness standards may violate EU anti-discrimination law. A system considered fair in one cultural context may be discriminatory in another.
3. Accountability and Liability
When an AI system causes harm, who is responsible?
This is not a simple question, and the legal frameworks to answer it do not yet exist in most jurisdictions. The liability chain for AI harm involves multiple parties: the company that developed the model, the company that deployed it, the company that configured it, and the user who relied on it. Current law struggles to assign responsibility across this chain.
Hallucination-driven financial loss is a growing concern. When an AI system confidently provides false information and a user makes a financial decision based on that information, who bears the loss? The model developer who did not prevent the hallucination? The deployer who did not add sufficient disclaimers? The user who did not verify?
Autonomous system failure raises even harder questions. When a self-driving vehicle causes an accident, is it the manufacturer's fault, the software developer's fault, or the operator's fault? When an autonomous trading system makes a catastrophic decision, who absorbs the loss? These questions are being resolved case by case, without consistent principles.
Legal recourse for AI-generated misinformation is virtually nonexistent. If an AI system generates false information about you, your options are limited. Defamation law requires proving intent, which is difficult to apply to a system that does not have intent. Product liability law requires proving a defect, which is difficult when the behavior is probabilistic by design.
4. Transparency and Explainability
Foundation models are black boxes. They produce outputs, but they cannot explain why.
This creates a fundamental tension between the commercial incentive to keep model internals proprietary and the societal need for accountability. Trade secrets versus transparency is not just a legal debate. It is a governance challenge that affects everyone subject to AI-driven decisions.
The right to explanation in automated decisions is established in principle by the EU's GDPR and AI Act, but the practical implementation is unclear. What constitutes an adequate explanation? A statistical summary of feature importance? A natural language description of the reasoning? A full disclosure of the model architecture and training data? Nobody has settled on a standard.
Independent auditing standards do not exist. Financial auditing has GAAP and IFRS. Safety auditing has ISO standards. AI auditing has nothing comparable. Organizations that claim their AI systems have been audited are using proprietary methodologies with no external validation framework.
This is not sustainable. As AI systems make more consequential decisions in healthcare, criminal justice, financial services, and government, the demand for transparency will intensify. Organizations that build transparency into their systems now will have an advantage when standards eventually arrive.
5. Security and Misuse
AI systems introduce new attack surfaces that traditional cybersecurity frameworks were not designed to address.
Model manipulation and adversarial attacks can cause AI systems to produce incorrect outputs without any visible indication that the system has been compromised. A subtle perturbation to an input image can cause a vision system to misclassify it. A carefully crafted prompt can cause a language model to bypass its safety guardrails. These attacks are well-documented in research and increasingly practical in deployment.
Data poisoning is a supply chain attack on AI systems. If an attacker can inject malicious data into a training dataset, they can influence the model's behavior in ways that are difficult to detect. The training pipelines for large models ingest data from diverse sources, and verifying the integrity of every data point is not feasible at scale.
AI-powered cyber threats are amplifying existing attack vectors. Phishing emails generated by language models are more convincing than manually written ones. Deepfakes are becoming harder to distinguish from genuine content. Automated vulnerability scanning powered by AI is accelerating the discovery of exploits.
Dual-use risks in defense and biosecurity represent the most consequential misuse scenarios. The same AI capabilities that enable drug discovery can be used to design harmful compounds. The same capabilities that power defensive cybersecurity can be used for offensive operations. Governance frameworks that address dual-use risks are in early stages at best.
6. Economic and Labor Impact
AI is reshaping labor markets at a pace that workforce policy cannot match.
Workforce displacement is not a future concern. It is happening now. Customer service, data entry, content creation, translation, basic legal research, and many other job categories are being automated or augmented at scale. The McKinsey Global Institute estimates that up to 30 percent of work hours could be automated by 2030.
Reskilling responsibility is unresolved. Who is responsible for retraining displaced workers? The companies that deploy AI systems? The governments that regulate them? The workers themselves? Current policy does not provide a clear answer, and the scale of reskilling required exceeds the capacity of existing programs.
AI concentration in large technology firms raises competitive concerns. The computational resources required to train frontier models are only available to a small number of companies. This creates a dynamic where AI capability is concentrated in firms that already dominate the technology sector, with implications for competition, innovation, and economic power.
Anti-trust implications are being explored but not yet resolved. When a handful of companies control the foundation models that power thousands of downstream applications, traditional competition frameworks may not be adequate. The market dynamics of AI are different from previous technology cycles, and regulatory tools are catching up.
7. Intellectual Property
AI has broken the assumptions that intellectual property law was built on.
Copyright ownership of AI outputs is unsettled. If a person uses an AI system to generate text, images, code, or music, who owns the output? The person who wrote the prompt? The company that built the model? Nobody? The US Copyright Office has ruled that purely AI-generated works cannot be copyrighted, but works with significant human involvement can be. The line between the two is unclear and will be litigated for years.
Use of copyrighted material in training is the subject of multiple active lawsuits. Authors, artists, musicians, and publishers are suing AI companies for using their work to train models without permission or compensation. The outcome of these cases will determine whether the current model of AI training is legally sustainable.
Synthetic impersonation risks are growing. AI systems can generate content that mimics a specific person's voice, writing style, likeness, or artistic approach. The legal protections against this kind of impersonation vary by jurisdiction and are often inadequate. When an AI can produce a convincing imitation of a living artist's work, the economic and reputational implications are significant.
8. Geopolitics and Sovereignty
AI has become a geopolitical issue with implications for national security, economic competitiveness, and international relations.
The AI arms race between nations is accelerating. The United States, China, the European Union, and other major powers are investing heavily in AI capabilities, driven by both economic ambition and security concerns. This competition is shaping policy decisions on export controls, research funding, immigration, and international cooperation.
Semiconductor export controls are a direct expression of AI geopolitics. The US restrictions on advanced chip exports to China are designed to slow China's AI development. The effectiveness and long-term consequences of these controls are debated, but their existence demonstrates that AI governance is now a matter of national security policy.
Compute concentration creates dependency. A small number of companies control the cloud computing infrastructure required to train and deploy large AI models. Countries that depend on foreign compute providers for their AI capabilities face sovereignty concerns. This is driving investment in domestic compute infrastructure in multiple countries.
Regulatory fragmentation across jurisdictions is creating compliance complexity. The EU AI Act, China's AI regulations, Canada's AIDA, and evolving US frameworks are not aligned. Organizations operating globally must navigate multiple, sometimes contradictory, regulatory regimes. There is no global AI governance framework, and prospects for one are limited.
The Governance Imperative
AI is no longer just a technological issue. It is a governance, economic, ethical, and geopolitical issue. Most AI systems today are being deployed faster than institutions can adapt. The regulatory frameworks are lagging. The auditing standards do not exist. The liability rules are unclear. The fairness standards are inconsistent.
This creates both risk and opportunity.
The risk is obvious. Organizations that deploy AI systems without adequate governance are exposed to regulatory, legal, reputational, and operational risk. The incidents will come. The question is whether you have the systems in place to prevent, detect, and respond to them.
The opportunity is less obvious but equally important. The next competitive advantage will not just be better models. It will be stronger governance architecture. Organizations that build robust AI governance systems now will be better positioned for the regulatory requirements that are coming, better protected against the incidents that are inevitable, and better trusted by the customers, partners, and regulators who increasingly demand accountability.
Building these systems is not optional. It is not a compliance exercise to be delegated and forgotten. It is a strategic capability that will separate organizations that thrive in the AI economy from those that are consumed by it.
The real question is not whether AI governance matters. The real question is whether we are building the guardrails as fast as we are building the systems they need to govern.
Right now, the answer is no.
That needs to change.
Why We Built Governance Into the Platform
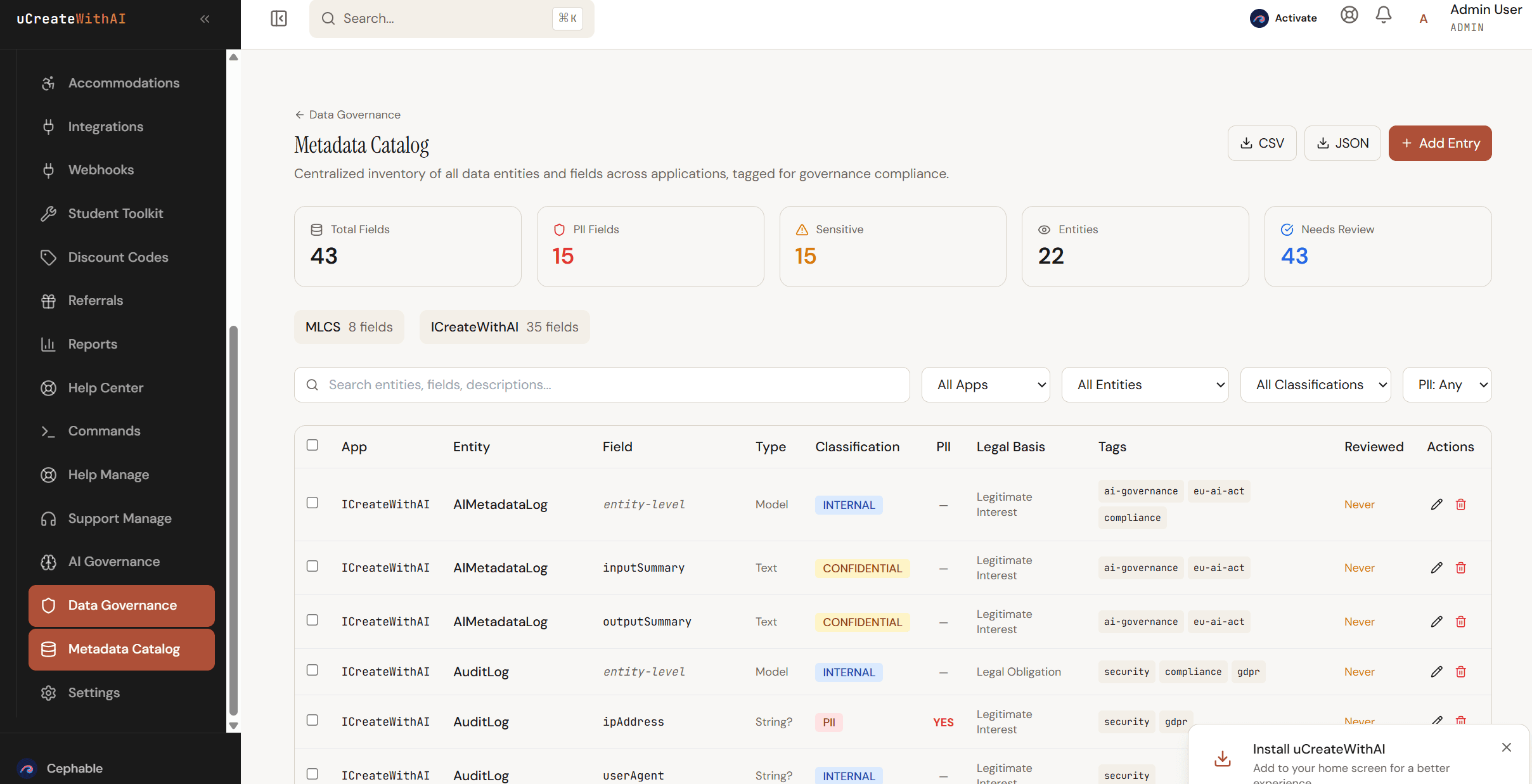
This is exactly why uCreateWithAI includes dedicated governance tracks — not as theoretical reading, but as hands-on courses where teams build the actual tools.
The AI Governance track teaches teams to build EU AI Act compliance systems, risk classification frameworks, and audit trail infrastructure using Claude Code. The Data Governance track teaches teams to build metadata catalogs, PII detection systems, GDPR compliance engines, and retention policy managers.
These are not abstract concepts. They are working systems built in the course, deployed to production, and designed to be adapted to your organization's specific requirements.
The governance gap is real. But it does not have to be permanent. The tools to close it exist. The question is whether you build them before the next incident forces you to.
Get posts like this in your inbox
No spam. New articles on AI strategy, governance, and building with AI for small business.
Keep Reading
Data and Metadata Governance in the Age of the EU AI Act: What You Should Be Doing Right Now
The EU AI Act doesn't just regulate AI models — it regulates the data that feeds them. Organizations that neglected data governance are about to pay the price. Here's what to prepare, what went wrong before, and why governing AI tools is no longer optional.
AI Governance Compliance in 2026: What Your Team Needs to Know
The EU AI Act enforcement begins August 2026. Here's how to prepare your organization.
Compliance Is Not a PDF You Buy
A YC-backed startup raised $32M to automate compliance. They issued 493 companies fraudulent SOC 2 reports in 6 months. Here's what that means for your business — and how to actually get compliant.